BigQuery 는 기본적으로 데이터 처리 능력이 뛰어난 데이터 웨어 하우스지만, 쿼리를 어떻게 작성하냐에 따라 성능이 달라진다.
일반적으로 작업량이 적은 쿼리의 성능이 더 우수하다.
쿼리 성능
BigQuery 에서의 쿼리 성능 평가에는 다음과 같은 몇가지 요소가 포함된다.
- 입력 데이터 및 데이터 소스(I/O) : 쿼리에서 읽는 바이트 수
- 노드 간 통신(셔플) : 쿼리에서 다음 단계로 전달하는 바이트 수, 쿼리에서 각 슬롯에 전달하는 바이트 수
- 계산 : 쿼리에 필요한 CPU 작업량
- 출력(구체화) : 쿼리에서 쓰는 바이트 수
- 사용가능 슬롯 수와 동시 실행 중인 쿼리 수
- 쿼리가 SQL 권장사항을 준수하는지
JOIN 최적화
Broadcast Join
방법 : 제일 큰 Table 을 Left에 두고, Right 에 가장 작은 Table을 위치하여 Broadcast Join 실행
데이터를 Join할 때 순서가 정말 중요한데, 가장 많은 Row를 가지고 있는 Table 을 먼저 배치한 후(LEFT), 그 다음 가장 적은 수의 Row를 가지는 Table을 배치하는 경우 Broadcast Join을 실행한다.
브로드캐스트 조인은 작은 Table 이 큰 Table을 처리하는 Slot 으로 전송되는 Join이다. 작은 Table의 데이터가 큰 Table 의 데이터가 저장된 Slot으로 이동하니 시간이 적게 소요된다.
브로드캐스트 조인을 먼저 진행하는 것이 좋다.
[TIP] 만일, Broadcast Join이 실행되지 않으면 Shuffled Join이 실행되는데, 이는 매우 큰 Join이고, 연산이 많이 소요된다.
Hash Join
두 큰 테이블을 Join할 경우, BigQuery나 Hash 또는 Shuffle 하여 일치하는 키가 동일한 슬롯에 위치되도록 만든 후, 조인한다. 데이터를 이동하느라 시간이 많이 소요되는데, 이런 경우 Clustering 을 한다면 Hash Join의 속도를 높일 수 있다.
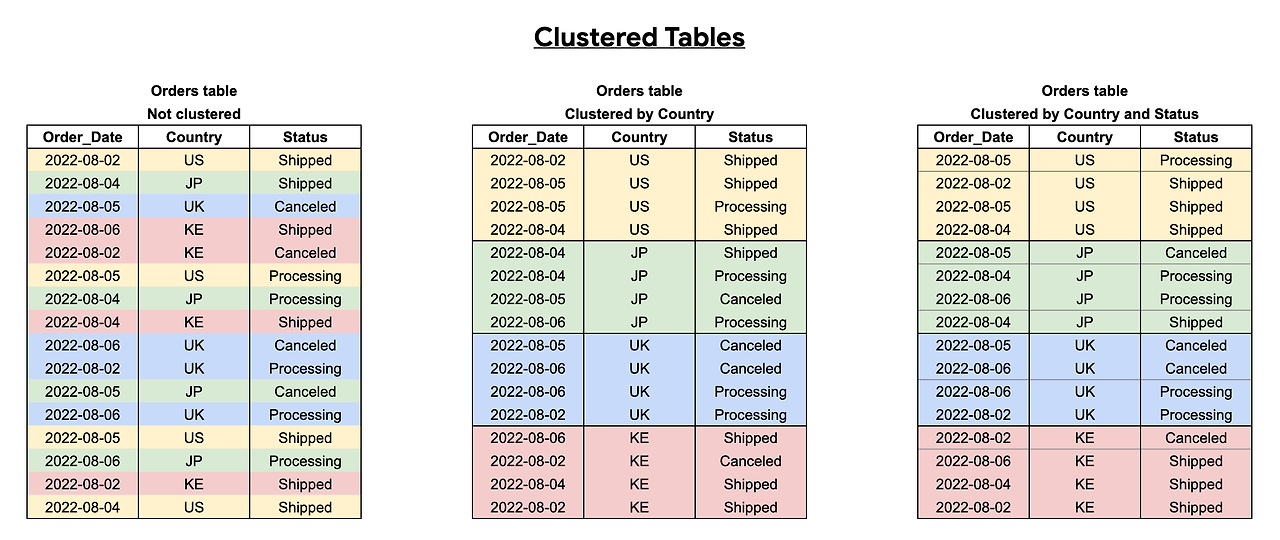
*클러스터링 된 테이블은 데이터를 셔플링하는 것과 동일한 효율을 보이기에 사용되곤 한다.
*클러스터링된 테이블
BigQuery의 클러스터링된 테이블은 클러스터링된 열을 사용하여 사용자 정의 열 정렬 순서가 있는 테이블이다. 이는 쿼리 성능을 높이고, 쿼리 비용을 줄일 수 있다.
Self Join
: 자신과 자신이 Join되는 경우로, 시간이 많이 소요되는 작업이거나 여러 곳에서 데이터를 가져와야 하므로 데이터가 더 많이 필요하다.
Analytics Function(윈도우 함수)를 사용할 수 있으면 사용하는 것을 추천
Cross Join
: 두 Table을 크로스하기 때문에 결과가 매우 큰 Table. WHERE 조건 등이 없다면 기존 Table보다 몇 배의 규모가 생성되어 실행이 안될 수 있다.
가능하면 미리 집계를 하거나, 배열을 사용하는 것을 추천 and 윈도우 함수를 사용하는 것 추천
UNNEST를 사용하는 쿼리는 Cross Join을 사용하는 형태
Skewed Join
Table 크기가 극단적으로 불균형할 때 발생할 수 있는 Join으로, 비대칭으로 인해 데이터 전송이 많이 발생
데이터를 미리 WHERE 조건으로 필터링하거나, 쿼리를 2개로 쪼개서 별도로 실행하는 것을 추천
* 피하기
*은 모든 컬럼을 의미하여 모든 컬럼을 탐색해야 하기 때문에 속도가 느려진다. 컬럼을 모두 사용하지 않으면 비용 관점에서 사용할 컬럼만 명시하는게 중요하다.
많은 컬럼을 반환해야 하는 경우, SELECT * EXCEPT 를 사용하면 된다.
StandardSQL
StandardSQL이 legacySQL 보다 빠르다고 한다.
쿼리에 맨 위에 #standardSQL을 명시하면 이 방식으로 쿼리가 실행되는데, default 지만, 간혹 과거 API를 사용한다면 LegacySQL을 사용하고 있을 수 있다.
반복적 데이터 전처리 피하기
정규 표현식을 사용하거나 SPLIT 함수 등을 한번 진행 후, 사용하는 것이 아닌, 매번 실행하는 경우 느려질 수 있다. 한번 집계를 한 후, 사용하는 것을 추천
참고 :
- 쿼리 최적화 | BigQuery Guide Book - 빅쿼리 가이드북 (zzsza.github.io)
- 클러스터링된 테이블 소개 | BigQuery | Google Cloud
- 쿼리 성능 최적화 소개 | BigQuery | Google Cloud
'공부' 카테고리의 다른 글
| [BigQuery] 빅쿼리 슬롯 및 SQL 쿼리 최적화 (1) | 2024.09.23 |
|---|---|
| [SQL] ROW_NUMBER() 함수 (1) | 2024.09.14 |
| [BigQuery] 빅쿼리 데이터 구조 및 기본적인 사용방법과 문법 (0) | 2024.09.13 |
| 파이썬의 enumerate() 내장 함수로 for 루프 돌리기 (2) | 2024.09.12 |
| [SQL} SELECT 문 정리 (FROM, WHERE, GROUP BY, ORDER BY, JOIN) (0) | 2024.09.11 |

