Voting
하드 보팅, Hard Voting
다수결 원칙과 비슷하다. 예측한 결괏값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결괏값으로 선정한다.
소프트 보팅, Soft Voting
분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결괏값으로 선정한다.

위와 같이 예측값이 확률로 산출될 경우 Hard Voting과 Soft Voting의 최종 예측 Class가 다르게 나올 수 있다.
일반적으로 하드 보팅보다는 소프트 보팅이 예측 성능이 좋아서 더 많이 사용된다.
Bagging, 배깅
배깅은 훈련 세트에서 중복을 허용하여 샘플링하는 방식, bootstrap aggregating의 줄임말이다. (↔페이스팅(pasting) : 중복을 허용하지 않는 방식)
각기 다른 훈련 알고리즘을 사용하는 Voting 방식과 달리 같은 알고리즘을 사용하고 훈련 세트의 서브셋을 무작위로 구성하여 분류기를 각기 다르게 학습시킨다.

배깅, 페이스팅 모두 같은 훈련 샘플을 여러 개의 예측기에 걸쳐 사용할 수 있다.
배깅만이 한 예측기를 위해 같은 훈련 샘플을 여러 번 샘플링 할 수 있다.
모든 예측기가 훈련을 마치면 앙상블은 모든 예측기의 예측을 모아서 새로운 샘플에 대한 예측을 만든다.
수집함수
- 분류 : 통계적 최빈값
- 회귀 : 평균
앙상블은 비슷한 편향에서 더 작은 분산을 만든다.
부트스트래핑(중복을 허용한 리샘플링)은 각 예측기가 학습하는 서브셋에 다양성을 증가시키므로 배깅이 페이스팅보다 편향이 조금 더 높다. 다양성을 추가한다는 것은 예측기들의 상관관계를 줄이므로 앙상블의 분산을 감소시킨다. 전반적으로 배깅이 더 나은 모델을 만들기 때문에 일반적으로 더 선호한다.
Boosting, 부스팅

약한 학습기를 여러 개 연결하여 강한 학습기를 만드는 앙상블 방법, 앞의 모델을 보완해나가면서 일련의 예측기를 학습시킨다.
AdaBoost, 에이다 부스트
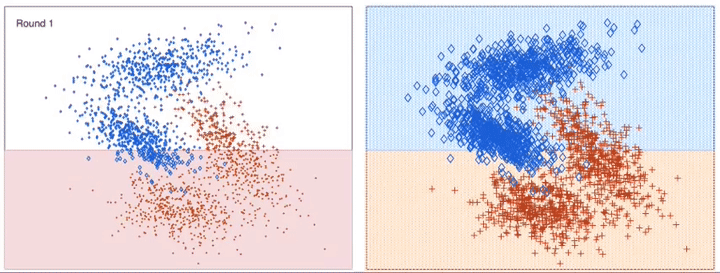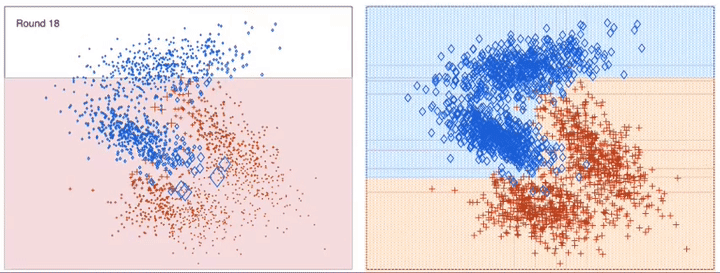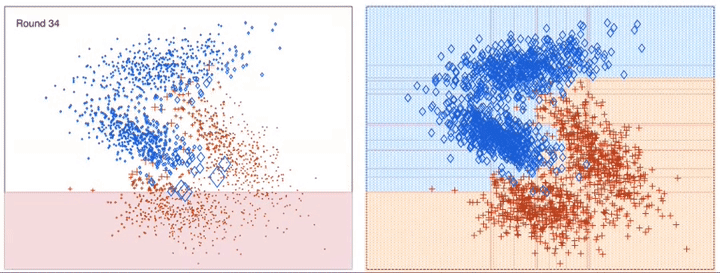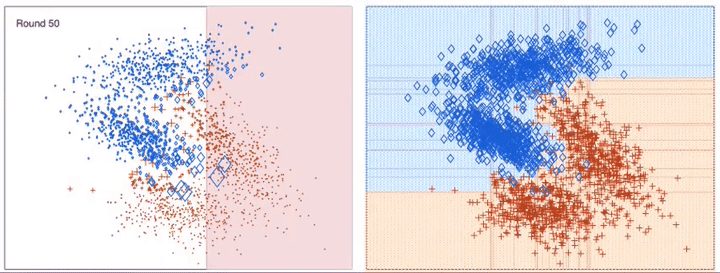
이전 모델이 과소적합했던 훈련 샘플의 가중치를 더 높여서 이전 예측기를 보완하는 새로운 예측기를 만든다. 이렇게 하면 예측기는 학습하기 어려운 샘플에 점점 맞춰지게 된다.
알고리즘이 기반이 되는 첫 번째 분류기(예로 결정 트리)를 훈련 세트에서 훈련시키고 예측을 만든다 그 다음에 알고리즘이 잘못 분류된 훈련 샘플의 가중치를 상대적으로 높인다. 두 번째 분류기는 업데이트된 가중치를 사용해 훈련 세트에서 훈련하고 다시 예측을 만든다. 그 다음에 다시 가중치를 업데이트한다.

각각 개별 약한 학습기는 가중치를 부여해 결합한다.
출처 :
https://helpingstar.github.io/ml/ensemble/
'공부' 카테고리의 다른 글
| [NLP] 한글 임베딩 (0) | 2022.12.28 |
|---|---|
| 머신러닝 강의 1편 (1) | 2022.12.21 |
| [NLP] Text Vectorization (작성중) (0) | 2022.09.08 |
| 상관계수의 종류 (0) | 2022.08.30 |
| [NLP] 모델 정확도 향상(keras.preprocessing vs nltk.tokenize) (0) | 2022.07.26 |

