임베딩은 텍스트를 단순하게 표현할 수 있어 다양한 통계적 자연어 처리기법에 적용되고 있습니다.
이번 컨텐츠에서는 Word2Vec에 대해서 알아보겠습니다.
1. 워드 임베딩(Word Embedding)
임베딩이란, 비정형화된 텍스트를 숫자로 바꿔줌으로써 사람의 언어를 컴퓨터 언어로 번역하는 것을 뜻한다.
1.1 희소표현(sparse representation)
: 원-핫 인코딩(one-hot encoding)을 통해 나온 원-핫 벡터(One-hot Vector) 처럼 벡터 또는 행렬의 값이 대부분이 0으로 표현되는 방법이다. 예를 들어 ‘나는 임베딩 공부를 하고 있다’는 문장을 희소 표현으로 나타내면 <그림1>의 (좌)과 같이 나타낼 수 있다.
- 고차원에 각 차원이 분리된 표현 방법

이는 표현하고자 하는 단어는 간단하게 나타낼 수 있는 장점이 있지만, 이는 단어 벡터 간 유의미한 유사도를 계산할 수 없다는 단점이 있다.
1.2. 분산 표현( distributed Representation)
희소 표현과 반대되는 개념으로, 단어의 의미를 다차원 공간에 벡터화 하는 방법
- 저차원에 단어의 의미를 여러 차원에다가 분산하여 표현
"단어 벡터 간 유의미한 유사도" OK
=> 워드투벡터(Word2Vec)
2. Word2Vec
워드임베딩(word embedding) : 분산 표현을 이용해 단어 간 의미적 유사성을 벡터화 하는 작업
임베딩 벡터(embedding vector) : 워드 임베딩으로 표현된 벡터
구글에서 개발한 Word2Vec은 분포 가설(distributional hypothesis)을 가정 하에 표현한 표현 방법이다.
분산 표현(Distributed Representation)
: 분포 가설(distributional hypothesis)이라는 가정 하에 만들어진 표현 방법
비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다
분산 표현은 분포 가설을 이용하여 텍스트를 학습하고, 단어의 의미를 벡터의 여러 차원에 분산하여 표현
- 은닉층이 1개인 얕은 신경망(shallow neural network)
- 활성화 함수 x
- 룩업 테이블이라는 연산 담당하는 층으로 추사층(projection layer)이라고 부름
2-1. CBOW(Continuous Bag of Words)
주변에 있는 단어들을 입력으로 중간에 있는 단어들을 예측하는 방법
목적 : W와 W'를 잘 훈련시키는 것
ex) The fat cat sat on the mat
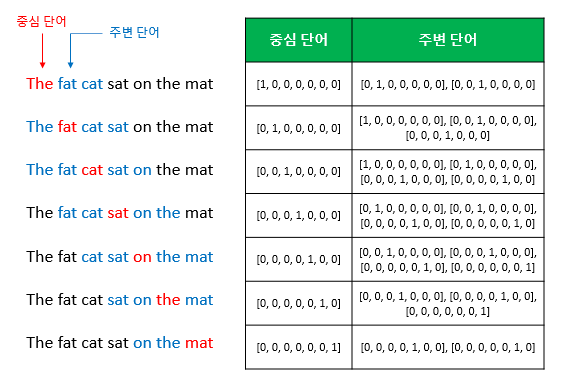
슬라이딩 윈도우(sliding window) : 윈도우를 옆에서 움직여서 주변 단어와 중심 단어의 선택을 변경해가며 학습을 위한 데이터 셋을 만드는 방법
입력 : 원-핫 벡터 주변 단어(윈도우 크기 x 2)
출력 : 원-핫 벡터 중심 단어

=> CBOW를 수행 한 후, 각 단어의 임베딩 벡터의 차원은 5
M : 투사층(projection layer)의 크기
V : 각 단어 집합의 크기
- 가중치 행렬 W와 W'는 랜덤 값
- CBOW 주변 단어로 중심 단어를 더 정확하게 맞추기 위해 W, W'를 학습하는 구조
* 두 행렬이 동일한 행렬을 전치(transpose)한 것이 아니라, 서로 다른 행렬

x : 각 주변 단어의 원-핫 벡터
입력 벡터 : 원-핫 벡터
입력벡터( i번째 인덱스에 1, 나머지 0), 가중치 W 행렬 곱 => W행렬의 i 번째 행을 그대로 읽어오는 것(lookup)
: 룩업 테이블(lookup table)
W, W' 잘 훈련시키는 것 => lookup 해온 W의 각 행벡터가 Word2Vec 학습 후에는 각 단어 M차원의 임베딩 벡터임
-

위와 같이 주변 단어의 원-핫 벡터에 대해 가중치 W가 곱해져서 생긴 벡터들은 투사층에서 평균의 벡터를 구함.
ex)
window size, n = 2면,
중간 단어를 예측하기 위해서 4개가 입력 벡터로 사용( 입력 벡터의 총 개수는 2n )
평균 : 4개의 결과 벡터를 평균으로 함
* 차이점 : 투사층에서 벡터의 평균을 구함

구해진 평균 벡터는 두번째 가중치 행렬 W'와 곱해짐.
곱셈 결과, 차원 : V ( 원-핫 벡터들과 동일 )
Step ]
CBOW는 소프트맥스(softmax) 함수를 지남.
벡터의 각 원소들의 값은 0-1사이의 실수, 총 합은 1
(다중 클래스 분류 문제를 위한 일종의 스코어 벡터) : 스코어 벡터의 j번째 인덱스의 0-1사이의 값은 j번째 단어가 중심 단어일 확률
두 벡터 값 오차를 줄이기 위해 CBOW는 손실 함수(loss function)로 크로스엔트로피(cross-entropy) 함수 사용
y헷 : 스코어 벡터
y : 중심 단어의 원-핫 벡터
V : 단어 집합의 크기
=> 값은 레이블에 해당하는 벡터인 중심 단어 원-핫 벡터의 값에 가까워져야 함

* 역전파(Back Propagation)를 수행하면 W, W'가 학습되는데, 학습이 다 되었으면
각 단어의 임베딩 벡터로 사용
- W( M차원의 크기)의 행렬의 행
OR W, W' 행렬 두 가지 모두를 가지고 임베딩 벡터를 사용
2. Skip-Gram
중심 단어들을 입력으로 주변 단어들을 예측하는 방법

* Skip-gram 이 CBOW 보다 성능이 좋다고 알려져 있음

NNLM : 다음 단어를 예측하는 언어 모델이 목적(예측 단어의 이전 단어들만 참고)
속도 느림
- 투사 > 은닉 > 출력
Word2Vec(CBOW) : 워드 임베딩 자체가 목적, 다음 단어가 아닌 중심 단어를 예측 (전, 후 단어 모두 참고)
속도 강점
- 은닉층 제거
- 계층적 소프트맥스(hierarchical softmax)와 네거티브 샘플링(negative sampling)
+ 출력층 연산에서 V를 log(V)로 바꿀 수 있는데, 이에 따라 빠른 학습 속도
Word2Vec : n x m + m x log(V)
참고
https://www.goldenplanet.co.kr/our_contents/blog?number=859&pn=1
GoldenPlanet | 빅데이터 공부 한 걸음: Word2Vec 이란?
Go Beyond Data! 골든플래닛
goldenplanet.co.kr
'공부' 카테고리의 다른 글
| 언제 MSE, MAE, RMSE를 사용해야 하는가? (1) | 2023.10.21 |
|---|---|
| 파이썬 선형 회귀 분석 결과 해석(OLS) (1) | 2023.10.15 |
| 채널톡 챌린저스 1기 해커톤 (0) | 2023.03.04 |
| SVM model에서 proba 값의 threshold != 0.5? (0) | 2022.12.28 |
| predict_proba 와 decision_function 차이점 (0) | 2022.12.28 |


