선형 회귀의 목적은 모든 데이터 포인트의 예측 오류를 최소화하는 선을 찾는 것이다.
MSE, MAE, RMSE는 모두 오차함수이다.
어떤 모델이 학습 데이터를 받아 아래 테이블 내 수치들을 예측했다고 생각하면,
target : 맞춰야할 정답
epoch : 학습의 횟수
Epoch 2에서 prediction의 3번째 값인 2는 Target의 3번째 값인 7와 크게 벗어나게 예측한 Outlier이다.

이들 값을 가지고 MSE, RMSE, MAE를 계산해보면 아래와 같다.

MSE(Mean Square Error)
평균 제곱 오차는 데이터 세트의 원래 값과 예측 값 간의 제곱 차이의 평균을 나타낸다.
가장 일반적이고 직관적인 에러 지표, 낮을수록 좋다.

잔차의 분산을 측정한다.
장점
- 지표 자체가 직관/단순
- 예를 들어, 삼성전자의 주가가 1000000원이고 네이버가 70000원일 때,
두 주가를 예측하는 각 모델의 MSE가 똑같이 5000이 나왔을 경우, 동일X, 동일하게 보여짐.
- 값의 왜곡 존재(에러를 제곱하기 때문에, 1미만의 에러는 더 작아지고, 그 이상의 에러는 더 커짐)
단점
- 스케일에 의존적
예측값과 정답의 차이를 제곱하기 때문에, 이상치(outlier)에 대해 굉장히 민감하다.
즉, 정답에 대해 예측값이 차이가 큰 경우에는, 그 차이는 오차값에 상대적으로 크게 반영된다.
오차값에 제곱을 취하기 때문에 오차가 0과 1사이인 경우에는 MSE에서 그 오차는 본래보다 더 작게 반영되고, 오차가 1보다 클 때는 본래보다 더 크게 반영된다.
모든 함수값이 미분 가능하다. MSE는 이차 함수이기 때문에 아래와 같이 첨점을 갖지 않는다.

RMSE(Root Mean Square Error)
평균 제곱근 오차는 평균 제곱 오차의 제곱근, 잔차의 표준편차를 측정한다.
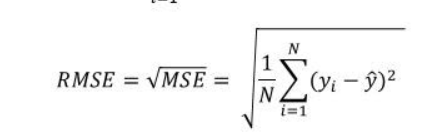
MSE의 값에 루트를 취한 값이다. (즉, 예측값과 정답의 차이를 제곱한 값에 루트)
그래서 오차가 0-1, 1보다 클 때의 반영의 정도가 다르다는 MSE의 단점이 어느정도 해소된다.
MSE는 부드러운 곡선형으로 오차 함수가 그려지지만, RMSE는 그 MSE에서 루트를 취하기 때문에 미분 불가능한 지점을 가진다. 아래 Figure 2는 RMSE 함수에 대한 예시이다.
MSE보다 이상치에 덜 민감하다. 이 RMSE는 이상치에 대한 민감도가 MSE, MAE 사이에 있기 때문에, 적절히 다룬다고 간주되는 경향이 있다.

MAE(Means Absolute Error)
평균 절대 오차는 데이터 세트의 실제값과 예측 값간의 절대 차이의 평균을 나타난다.

데이터 세트의 잔차 평균을 측정한다.

MSE, RMSE에 비해 오차값이 outlier의 영향을 상대적으로 크게 받지 않아, 이상치에 둔감한 편이다.(robust)
함수값에 미분 불가능한 지점이 있다.
모든 오차에 동일한 가중치를 부여한다.

3가지 손실 함수에 대한 비교 분석
MSE는 이상치에 대해 너무 민감하여, 모델의 학습을 불안정하게 만들 가능성이 크다.
real world의 많은 이상치가 있는 데이터에 대해서, MSE를 이용한다면, 이상치에 민감하게 학습되기 때문에 학습 과정이 불안정할 수도 있다.
이 불안정성은 결국 모델의 fitting을 방해하여 목적에 맞는 좋은 성능 모델을 얻는데 좋지 않은 영향을 미칠 수 있다.
MSE에 루트를 취하여 이상치에 대한 민감도를 줄인 RMSE와 절대값을 취하는 MAE는 어떤 차이가 있을까?
MAE는 오차들의 절댓값의 평균을 계산하는 점에서, 모든 examples에 대한 오차에 동일한 가중치를 부여한다.
RMSE는 각 example에 제곱을 취한 뒤 평균을 구한 값에 루트를 씌우는 것이기 때문에, 각 오차가 다른 가중치를 갖는다.

오른쪽 경우에 각 example에 대한 오차는 모두 동일하게 가중되어 고려되고 있다.
반면, 왼쪽 그래프인 RMSE는 0-1사이의 오차는 더 작게, 1보다 큰 오차는 더 크게 가중되어 고려되고 있다.
하나의 Outluer가 있는 경우, MAE는 다른 examples과 outlier를 동일하게 가중하여 고려하기 때문에 비교적 loss값이 낮게 나오지만, RMSE 경우에는 루트를 취했음에도 불구하고, outlier가 다른 examples 보다 가중되어 고려되기 때문에 비교적 loss값이 크게 나타난다.(MSE는 더 크게 나타났을 듯)

많은 모델에서 RMSE는 MAE보다 해석하기 어렵지만 손실 함수 계산을 위한 기본 측정 항목으로 사용된다.
RMSE는 MAE처럼 미분 불가능한 지점을 갖지 않기 때문에, 최적화시에 더 좋은 모델을 만드는 데 이점을 갖는다고 한다.
RMSE는 왜 미분 불가능 지점이 없는데?
RMSE는 미분 불가능한 영역을 갖는 것 같다.
RMSE는 아래와 같이 식이 전개되는데,

만약, N = 2인 경우, f(x, y) = sqrt(x^2 + y^2)로 간주할 수 있다.
x는 한 example에 대한 error 제곱을 가리키고, 이변수함수는 아래와 같이 표현된다.

위 그림은 첨점(sharp point)를 갖기 때문에, 빨간선 x축, 초록선을 y축이라 하면 원점에서 미분이 불가능하다.

즉, RMSE 역시 미분 불가능한 영역을 갖고 있다. MAE, RMSE 원점 근방이 완만하기 않기에 모두 미분 불가능한 영역을 갖고 있다. ??
언제 어떤 loss를 사용하나?
약간의 이상치가 있는 경우, 그 이상치의 영향을 적게 받게모델을 만들고자 할때, MAE를 쓰는 것이 적절하다.
MAE는 이상치에 대해 강건(robust)하기 때문에 이상치에 영향을 덜 받는다. 이는 이상치를 포함한 훈련 데이터에 적합하게 학습되어 unseen 데이터에 대해 낮은 성능을 보이게 하는 오버 피팅을 방지하는데 도움이 될 수 있다.

MSE의 경우 이상치에 민감하게 반응하여 학습하기 때문에, 손실 함수가 이상치에 의해 발생한 오차로부터 비교적 많은 영향을 받는다.

그러면, 이상치까지 고려하여 모델 일반화가 이루어진다. 이것은 모든 경우에 일반화를 제대로 하지 못했다고 간주될 수는 없는데, 어떤 경우에는 이상치를 무시하여 일반화할 필요가 있고(MAE), 어떤 경우에는 이상치도 고려하여 일반화(MSE)할 필요가 있기 때문이다.
RMSE는 MSE보다 이상치에 대해 상대적으로 둔감한데, 이는 MAE처럼 모든 error에 동일한 가중치를 주지 않고, error가 크면 더 큰 가중치를, 작으면 더 작은 가중치를 주어서 여전히 이상치에 민감하다고 간주될 수 있다. 따라서 모델 학습 시 이상치에 가중치를 부여하고자 한다면, MSE에 루트를 씌운 RMSE를 채택하는 것이 좋다.
즉, RMSE는 MAE에 비해 직관성은 떨어지지만 Robust한 성격(극단적이지 않은 성격)에서 강점을 보인다.
참조
- https://jmlb.github.io/flashcards/2018/07/01/mae_vs_rmse/
'공부' 카테고리의 다른 글
| 신뢰 구간(Confidence Intervals), stats.t.interval python 사용법 (0) | 2024.01.02 |
|---|---|
| [하향식 네트워크] 4-2. Web and HTTP (0) | 2023.10.25 |
| 파이썬 선형 회귀 분석 결과 해석(OLS) (1) | 2023.10.15 |
| 워드투벡터(Word2Vec) (1) | 2023.10.04 |
| 채널톡 챌린저스 1기 해커톤 (0) | 2023.03.04 |


