HTTP(Hypertext Transfer Protocol)

web page는 URL로 할당된 많은 참조된(referenced) 객체(objects)이 포함되어 base HTML-file로 구성되어 있다.
HTTP는 웹의 application layer protocol이며, Client-Server model을 사용한다.
Client-server model
클라이언트(Client)는 호스트(host)에서 실행되는 브라우저가 되며, 웹 서버와 통신한다.
HTTP protocol을 사용해 요청하고 응답받으면서 웹의 객체(objects)를 표시한다.
*object는 HTML file, JPEG image, Java applet, audio file, ... 이 될 수 있다.(각기 다른 웹서버에 저장되어있음)
서버(Server)는 웹 서버로, HTTP protocol을 사용하여 요청에 응답할 때 객체를 전달한다.
-
HTTP는 TCP를 사용하며, 다음과 같은 단계를 가진다.
1) 클라이언트가 port 80를 사용하여 서버에 대한 TCP connection을 초기화한다. (소켓을 생성, create socket)
2) 서버는 클라이언트의 TCP 연결을 허락(server accepts TCP connection from client)
3) 브라우저(HTTP 클라이언트)와 웹 서버(HTTP 서버) 사이에 HTTP 메세지( 어플리케이션 메세지 프로토컬 메세지, application-layer protocol message) 가 교환된다.
4) TCP 연결이 닫힌다.
HTTP는 stateless 하다.
즉, 서버는 과거 클라이언트 요청에 대한 어떠한 정보(history)도 유지하지 않는다.
클라이언트의 모든 state를 유지하는 것은 복잡하기에 서버에 매우 큰 부담이다.
그러니. 과거의 정보(history, state)를 유지하는 것은 필수적이다.
만약에 서버와 클라이언트가 충돌할 경우, 'state'가 일정하기 않을 수 있기 때문에 확인이 필요하다.
HTTP connections
HTTP 연결 방식은 두가지가 있다.
Non-persistent HTTP
동작방식
1) 서버에서 TCP 연결(TCP connection)을 연다.
2) TCP 연결을 통해 최대 하나의 객체를 전송한다.
3) TCP 연결을 닫는다.
따라서 다수의 객체를 다운로드하려면 다수의 연결이 필요하다.
아래는 사용자(User)가 "https://www.someschool.edu/someDepartment/home.index"라는 URL에 들어갔을 때의 예제이다.
해당 URL에는 text와 참조된(references) 10r개의 JPEG 이미지가 있다.

1-1) HTTP 클라이언트가 특정 주소( www.someSchool.edu )의 HTTP 서버에 대한 TCP 연결을 초기화 한다. (80 포트 사용)
1-2) 특정 주소( www.someSchool.edu )의 호스트 HTTP 서버는 80 포트의 TCP 연결을 기다리고 있었다가,
클라이언트가 요청을 보내면 연결을 허락하고 알려준다.
2) HTTP 클라이언트는 URL을 포함한 HTTP request message를 TCP 연결 socket에 보낸다.
메세지는 클라이언트가 어떤 객체를 요구하는지에 대한 정보가 담겨 있다.
위의 예제에서는 " someDepartment/home.index " 에 대한 object를 원한다.
3) HTTP 서버는 request message를 수신하고, 요청한 객체(requested object)가 담긴 response message를 만들어 서버의 socket으로 보낸다.
4) HTTP 서버가 TCP연결을 닫는다.
5) HTTP 클라이언트는 html 파일이 포함된 response message를 수신하고, html을 보여준다.
받은 html을 파싱하여 10개의 참조 객체를 확인한다.
6) 이 참조 객체를 위해 위의 1-5 step을 반복한다.
Persistent HTTP
(= HTTP 1.1)
동작 방식
1) 서버 쪽에서 TCP 연결을 연다.
2) 클라이언트와 서버 사이에 단일 TCP 연결을 통해 다수 객체를 전송할 수 있다.
3) TCP 연결을 닫는다.
Persistent HTTP는 서버가 response를 보내고 나서도 연결을 닫지 않고 유지한다.
이후, 같은 클라이언트-서버 간 HTTP 메시지가 열린 연결을 통해 전송된다.
클라이언트가 참조 객체를 확인하면 즉시 request를 보낸다.
Response time
RTT(Round-Trip Time) : 클라이언트로부터 서버까지, 하나의 패킷이 이동하는 시간
HTTP의 두가지 형식 중 하나인 Non-persistent HTTP를 계산해보자.
Non-persistent HTTP : response time

TCP 연결 초기화 : 1 RTT
HTTP 요청 및 첫번째 요청에 대한 HTTP response : 1 RTT
객체(object)/파일 전송 시간 : file transmisstion time
을 모두 더한 시간이다.
Non-persistent HTTP response time = 2RTT + 파일 전송 시간
이는 한 객체당 2RTT + @의 시간이 필요하다는 것이며,
브라우저가 다수의 참조 객체들을 가져오기 위해서 병렬 TCP 연결을 하기 때문에, OS 오버헤드가 발생한다.
Persistent HTTP : response time
반면, Persistent HTTP는 연결을 유지하기 때문에, 참조 객체에 대해 1 RTT만 소요된다.
예제 문제>
문제 1) 병렬 TCP 연결을 적용하지 않은 Non-persistent HTTP의 response time은?
base html-file을 받는데 걸리는 시간 : 2 RTT
TCP 연결 초기화 ( 1 RTT ) + base html file 요청 및 수신 ( 1 RTT )
8개의 참조 객체를 받기 위해서는 TCP 연결을 열고 닫고를 반복한다.
각 객체당 2RTT가 걸리므로 ( TCP 연결 초기화 ( 1 RTT ) + base html file 요청 및 수신 ( 1 RTT ) )
2RTT + (2RTT x 8) = 18 RTT
+@로 참조 객체의 파일 전송 시간까지 더해지지 않을까 싶다.
문제 2)
클라이언트에서 웹서버로 하나의 HTML파일을 요청한다. 요청한 HTML파일은 6개의 이미지들을 참조하고, 해당 이미지들은 HTML파일이 위치한 동일한 웹서버에 위치한다. 클라이언트는 웹서버로부터 HTML파일을 먼저 전달받은 후에, HTML파일이 참조하는 이미지들을 웹서버에 요청한다고 가정한다. HTML파일의 크기는 20,000비트이고, 각 이미지는 400,000비트이다. 다운로드율을 2,000,000비트/초이고, 클라이언트와 서버사이의 RTT는 0.1초이다. 다음 조건에서 이미지를 포함하는 전체 HTML파일을 얻는데 걸리는 시간은 얼마인가?
단, 어떤 DNS질의(query)도 하지 않으며 HTTP메시지의 요청라인과 헤더는 무시할 정도라고 가정한다. 그리고, 병렬연결(parallel connections)을 사용하지 않는 지속적(persistent) HTTP일 경우를 고려한다.
(chatGPT로 물어봤는데, 멍청해서 내가 다시 풀어서 정리했다.)
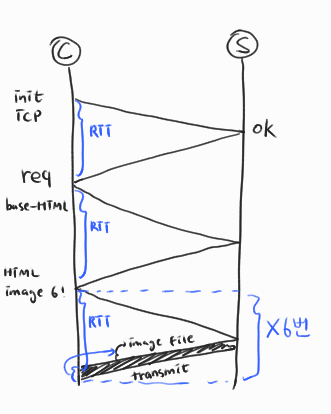
내가 직접 그린 그림인데, 이런식으로 진행이 되는 것 같다.
TCP 연결 초기화 : RTT
base-HTML 요청 : RTT
Time to transmit file : base-html transmit time
병렬연결(parallel connections)을 사용하지 않지만, 지속적(persistant) HTTP이기 때문에 TCP 연결 초기화는 계속해줄 필요가 없다.
대신, 병렬 연결을 사용하지 않기 때문에계속해서 이미지 파일에 대한 요청을 해야 한다.
해당 HTML의 참조된 이미지 : RTT + image file transmit time
base-HTML transmit time : L/R
= 20,000bit(HTML 크기) / 2,000,000bit/sec (다운로드율)
= 0.01 sec
time to transmit image file) : L/R
= 400,000bit(이미지 크기) / 2,000,000bit/sec (다운로드율)
= 0.2 sec
이미지를 포함하는 전체 HTML파일을 얻는데 걸리는 시간
= 2RTT + base-HTML transmit time + (RTT + time to transmit file) x 6
= 2(0.1sec) + 0.01sec + (0.1 sec + 0.2 sec) x 6
= 0.2 sec + 0.01 sec + 1.8 sec
= 2.01 sec 이다.
HTTP message (request/response)
HTTP message에는 request, response의 두가지 종류가 있다.
HTTP 요청 메시지의 일반 포맷
HTTP 클라이언트, 서버가 보내는 메시지의 형식은 아래와 같다.

request line, header line, body로 나누어져있다.
요청 라인(request line) : HTTP 요청 메시지의 첫줄
- 3개의 필드(method, URL, HTTP version)
- 방식(method) 필드 : GET, POST, PUT, DELETE를 포함한 여러 가지 값을 가짐
method 의 종류는 아래와 같다.
GET method
entity body가 없어, 서버에 데이터를 보내기 위해서는 URL 필드를 통해서 전달
ex) https://www.somesite.com/animalsearch?monkeys&banana 이면, "monkeys&banana"라는 데이터를 전달
POST method
웹 페이지에 입력이 있을 때, HTTP POST request 메시지의 entity body에 클라이언트의 input을 넣는다.
HEAD method
- HTTP GET 메서드를 사용하여 URL이 요청된 경우 반환되는 헤더만 요청
- 서버가 해당 HEAD 요청을 받으면 HTTP 메세지로 응답하되, 요청 객체는 전송 X
- 어플리케이션 개발자는 디버깅을 위해 HEAD 메소드 많이 사용
PUT method
- 서버에 객체 업로드
- 웹 서버에 업로드할 객체를 필요로 하는 애플리케이션에 의해 사용
DELETE method
- 사용자 또는 애플리케이션이 웹 서버에 있는 객체를 지우는 것을 허용
HTTP 응답 메시지
[request line]
method : GET (POST, HEAD, PUT, DELETE가 있음)
url : index.html
version : HTTP/1.1 버전
[header line]
(중요한 부분만 언급하겠다.)
User-Agent : Firefox/3.6.10
=> 서버에게 요청하는 브라우저 타입 명시. 만약에 구글이면 Google, 엣지면 Edge일 것이다.
connection : keep-alive
=> persistant 유형이다. 만약에 closed일시에는 non-persistant 이다.
[entity body] :사용자가 form 필드에 입력한 것을 포함
- POST 방식에서 사용(GET 방식에서는 비어 있음)
- HTTP 클라이언트는 사용자가 폼을 채워넣을 때 POST 방식 사용
GET /index.html HTTP/1.1\r\n // 요청 라인(request line)
// --- 헤더 라인(header line)
Host: www-net.cs.umass.edu\r\n
User-Agent: Firefox/3.6.10\r\n
Accept: text/html,application/xhtml+xml\r\n
Accept-Language: en-us,en;q=0.5\r\n
Accept-Encoding: gzip,deflate\r\n
Accept-Charset: ISO-8859-1,utf-8;q=0.7\r\n
Keep-Alive: 115\r\n
Connection: keep-alive\r\n
\r\n
// ---------------------------
메시지가 일반 ASCII 텍스트로 쓰여 있어 사람들이 읽을 수 있다.
CR(carriage return character ( = \r)), LF(line feed character ( = \n ))로 구별된다.
- 마지막 줄에 추가 CR, LF가 따른다.
- 요청 메시지는 더 많은 줄로 구성되거나 하나의 줄로 될 수 있다.
3개의 섹션으로 나누어져있다.
[status line(protocol / status code / status phrase)]
- 상태 라인은 3개의 필드( 버전 필드 / 상태 코드 / 해당 상태 메시지 )를 가진다.
- 아래 예시에서 서버는 HTTP/1.1 사용, 양호하다는 의미
200 OK : 요청이 성공했고, 정보가 응답으로 보내졌다.
301 Moved Permanently : 요청 객체가 이동되었다.
- 새로운 URL은 응답 메시지의 Location: 헤더에 나와 있음
- 클라이언트 소프트웨어는 자동으로 새로운 URL을 추출한다.
400 Bad Request : 서버가 요청을 이해할 수 없다.
404 Not Found : 요청 문서가 서버에 존재하지 않는다.
505 HTTP Version Not Supported : 요청 HTTP 프로토콜 버전을 서버가 지원 X
[header lines]
Date : HTTP 응답이 서버에 의해 생성되고 보낸 날짜와 시간을 나타냄
Server : 메시지가 아파치 웹 서버에 의해 만들어졌음을 나타냄
(HTTP 요청 메시지의 User-agent 헤더라인과 비슷)
Last-Modified : 객체가 생성되거나 마지막으로 수정된 시간과 날짜를 나타냄
등등
[data, requested HTML files]
body에는 요청 객체(data data, ... )를 포함한다.
HTTP/1.1 200 OK\r\n // 초기 상태 라인
// 헤더 라인 -------------------------------
Date: Sun, 26 Sep 2010 20:09:20 GMT\r\n
Server: Apache/2.0.52 (CentOS)\r\n
Last-Modified: Tue, 30 Oct 2007 17:00:02 GMT\r\n
ETag: "17dc6-a5c-bf716880"\r\n
Accept-Ranges: bytes\r\n
Content-Length: 2652\r\n
Keep-Alive: timeout=10, max=100\r\n
Connection: Keep-Alive\r\n
Content-Type: text/html; charset=ISO-8859-1\r\n
\r\n
// ----------------------------------------
// 객체 body
data data data data data ...
'공부' 카테고리의 다른 글
| 히스토그램(histogram) - 시각화를 어느 상황에서 사용하면 좋을까? (1) | 2024.01.03 |
|---|---|
| 신뢰 구간(Confidence Intervals), stats.t.interval python 사용법 (0) | 2024.01.02 |
| 언제 MSE, MAE, RMSE를 사용해야 하는가? (1) | 2023.10.21 |
| 파이썬 선형 회귀 분석 결과 해석(OLS) (1) | 2023.10.15 |
| 워드투벡터(Word2Vec) (1) | 2023.10.04 |


