*참고
T-test(T 검정)
: 두 집단 간의 평균 차이가 유의미한지 검증하는 보편적인 통계 방법
평균을 비교하는 이유가 무엇일까?
평균은 한 집단을 대표할 수 있는 대푯값 중 하나이다. 두 모집단의 평균 차이 유무를 판단하는 통계적 검정 방법으로 단순히 차이의 존재 여부를 떠나 그 정도의 통계적 유의미성까지 검정하는 방법이다.
그렇다면 두 집단이 아니라, 세집단 혹은 그 이상이라면 T-test를 사용하면 안된다. "두 모집단의 평균의 차이유무"를 비교하는 것은 T-test이니, 이 경우에는 분산분석 즉, ANOVA(Analysis Of Variance)를 사용한다.
t-test의 조건
조건 1] 표본이 독립적인가? (t-test or paired t-test)
조건 2] 수집된 데이터가 정규 분포를 따르는가? (t-test or Wilcoxon test)
조건 3] 집단이 두 개인가? (t-test or Anova)
막대 그래프, 히스토그램이란?
막대 그래프
범주(category)로 구분되는 데이터를 표현하는데 사용한다.
막대로 표현하려는 범주의 순서는 의도에 따라 바뀔 수 있다.
히스토그램이란?
히스토그램 그래프
연속형 데이터를 사용자 지정 범위로 응축하여, 도수의 분포 상태의 차이를 쉽게 알아볼 수 있도록 그린 그래프이다.
정보를 보다 효율적으로 전달할 수 있도록 많은 양의 데이터를 읽기 쉬운 그래프로 요약한다.
장점
- 데이터의 특정 수가 많고 적음을 한눈에 알아보기 쉽다.
- 정규분포와 비교하기 쉽다
단점
- bin 설정으로 원래 값을 상실할 수 있다.
- 두 데이터셋을 비교하기 어렵다.
- 연속적인 데이터에서만 사용 가능하다.
KDE(Kernel Density Estimator)란
: 데이터를 바탕으로 하는 밀도 추정으로 데이터마다 커널을 생성한 히스토그램
히스토그램을 그릴 때, KDE를 같이 들고가면 됨
상자 수염(Boxplot) 그래프
Boxplot은 상자 수염, 상자수염그림, 상자그림 등등 다양한 이름을 가진 차트이다.
(우리 교수님은 상자 수염 그래프라고 칭하시더라,,)
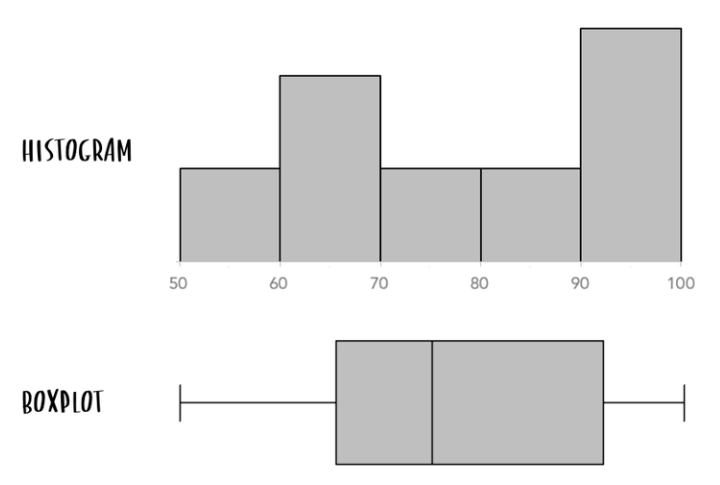
보통 90도를 회전시켜서 히스토그램과 같이 비교하면서 시각화 한다.
상자 수염 그래프는 데이터의 분포와 이상치를 동시에 보여주면서 서로 다른 데이터군을 쉽게 비교할 수 있는 데이터 시각화 유형이다. 데이터를 그대로 보여주는 것보다는 다섯숫자요약(Five-Number Summary)라는 통계학적 개념으로 데이터를 가공하여 분포에 대한 통계치를 시각화한다.
( 얼마나 데이터가 펴져 있고, 중앙값에 몰려있고, 이상치가 있는지를 판단할 수 있다. )
다섯숫자요약이란 다섯가지 통계로 데이터를 나타내는 방법이다.
최솟값(minimum), 최댓값(maximum) 그리고 제1사분위수(Q1), 제2사분위수(Q2, 중앙값), 제3사분위수(Q3)로 구성된다. 박스 수염 그래프는 이 다섯숫자요약의 개념을 바탕으로 데이터를 시각화해서 보여주는 차트이다.
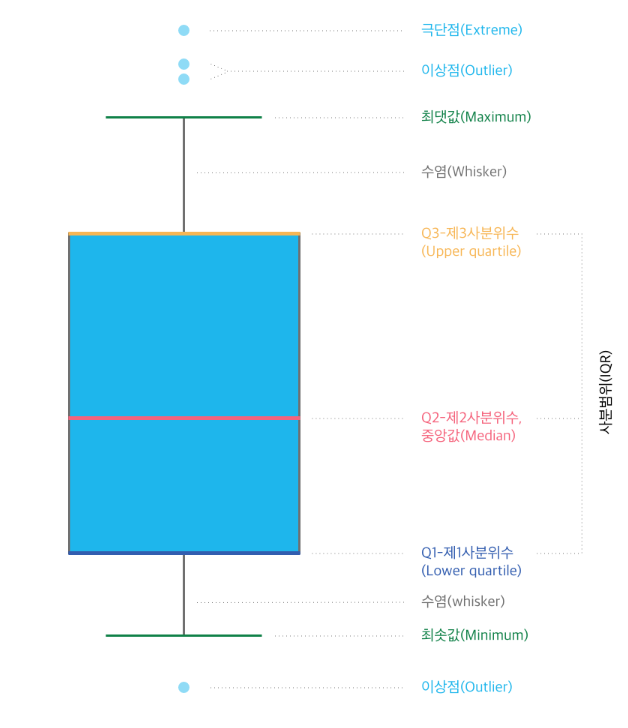
박스 수염 그래프에서 제2사분위수(중앙값)은 중요한 수치이며, 2사분위수를 기준으로 데이터의 50%가 상위, 나머지 50%가 하위에 분포되어 있음을 뜻한다. 가운데 상자는 중앙값을 기준으로 상하위 25% 지점에 있는 데이터의 범위를 표시한다. (25%-75%) 전체 데이터를 작은 값에서 큰 값으로 나열했을 때 전체 데이터의 25% 지점은 1사분위수, 75% 지점은 3사분위수를 나타낸다.
상자의 양 끝에 연결된 선은 수염이라고 불리는데, 이 수염은 상자 길이(IQR)의 1.5배만큼 떨어진 지점을 나타낸다.
이상치 경계 : Q3 + 1.5*IQR, Q1-1.5*IQR
IQR(inte) : 범위를 이야기함

Q1, Q2, Q3란
가운데 있는 네모 박스를 보면, 세개의 세로줄이 있고, Q1, Q2, Q3라고 되어있다.
Q는 quartile 의 앞글자로, 전체를 넷으로 나눈 수라는 뜻의 사분위수라는 것이다.
사 : 넷으로 / 분 : 나누는 / 위 : 위치에 있는 / 수 : 숫자

이 세 사분위수를 각 1, 2, 3사분위수라고 부른다.
전체를 같은 간격으로 나누기 때문에 1사분위수는 전체 데이터의 25%의 위치, 2사분위수는 50%의 위치, 3사분위수는 75%의 위치에 있다. 예를 들어 전체 데이터의 크기가 100개가 있으면, 크기 순으로 25번째 데이터까지가 1사분위수, 50번째 데이터가 2사분위수, 75번째 데이터 크기까지 3사분위수가 된다. 2사분위수는 중앙값과 같다.
Q1 : 1사분위수 (25% 위치)
Q2 : 2사분위수 (50% 위치)
Q3 : 3사분위수 (75% 위치)
IQR이란
IQR은 Interquartile range의 줄임말로, 우리말로는 사분위범위라고 부른다. 사분위수의 범위라는 것인데, 3사분위수에서 1사분위수를 뺀 값으로 정의된다.
IQR = Q3 - Q1
위의 파란색 글씨 부분이 IQR의 값을 의미한다.
이상치란?
이상치는 말 그대로 이상한 값인데, Outlier라고 한다. 다른 관측치와 값이 크게 다른 값이다.
Q3 + 1.5 x IQR 보다 큼
Q1 - 1.5 x IQR 보다 작음
최댓값, 최솟값
상자수염그림에서 최댓값은 이상치를 제외한 값들 중 가장 큰 값을 말한다. 최솟값도 이상치를 제거한 값들 중 가장 작은 값이다.
사용하는 이유
보통 우리가 통계를 낼 때 평균이나 표준편차를 많이 사용하는데, 이런 경우 데이터에 이상치가 있으면 왜곡된 의미를 전달할 가능성이 높다. 그래서 이상치가 있는지 확인할 필요가 있고, 박스플롯을 활용하면 이상치가 얼마나 포함되어 있는지 쉽게 판단할 수 있다.
전체 데이터의 항목별 분포를 보고 싶으면 히스토그램(Histogram)을 선택하는 것이 더 유용할 수도 있다. 데이터의 값이 둘 이상의 점 주위에 모여있는 경우, 박스플롯으로는 구분하기 어려울 수 있기 때문이다.
그러면 바이올린 그래프에 대해서 알아보겠다.
아래 그림은 왼쪽이 박스 플롯, 오른쪽이 바이올린 플롯이다.
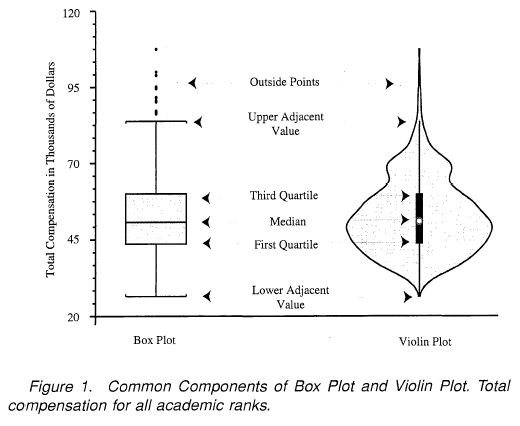
바이올린 그래프(violin plot)
박스 플롯과 동일하게 연속형 데이터의 분포를 설명하기 위해 사용되는 그래프이다. 대부분의 내용은 박스 플롯과 같으며, 커널 밀도 곡선(KDE, Kernel Density Curve)와 박스플롯을 합친 형태이다.
카테고리값에 따른 각 분포의 실제 데이터, 전체 형상을 보여준다는 장점이 있다.

이상치가 존재하면 선이 끝까지 안 올라가는데, 이상치가 없을 때는 끝점에 맞아 떨어진다.
박스 플롯이 가지고 있는 것 + 데이터 분포를 알리고 싶을 때 사용한다.
- 정보가 더 많고,
- 데이터의 분포를 보여주고 싶을 때
그러나, 데이터가 요동치고 있다는 것을 보여주고 싶지 않을 때는 사용하지 않는다.
참고
- https://www.storytellingwithdata.com/blog/what-is-a-boxplot
- https://newsjel.ly/archives/newsjelly/14177
- https://www.edrawsoft.com/kr/for-beginners/what-is-histogram.html
- https://sohyunwriter.tistory.com/142
'공부' 카테고리의 다른 글
| 신뢰 구간(Confidence Intervals), stats.t.interval python 사용법 (0) | 2024.01.02 |
|---|---|
| [하향식 네트워크] 4-2. Web and HTTP (0) | 2023.10.25 |
| 언제 MSE, MAE, RMSE를 사용해야 하는가? (1) | 2023.10.21 |
| 파이썬 선형 회귀 분석 결과 해석(OLS) (1) | 2023.10.15 |
| 워드투벡터(Word2Vec) (1) | 2023.10.04 |


